A QUIC retrospection on HTTP/2


You may have heard this term "QUIC" floating around the Internet, and not known what to do with it. Is it an adverb? An acronym? A bad pun? And what does it have to do with HTTP/2? Let's do a QUICk survey and find out. This will be the first of a pair of posts; part 2 is here.
Way back when I joined the Web Protocols team at Microsoft, we were just getting started with HTTP/2. There had been several proposals offered to the HTTPbis working group as a starting point, and the working group had just selected Google's experimental SPDY protocol to become HTTP/2 draft 00. My manager sent me a pointer to the draft and asked me to read and comment; I sent back a list of things that I had questions about or which didn't make sense to me later that afternoon.
And that started a crazy two years from first sending a few of my questions to the WG mailing list to finally getting the RFCs published. I started participating on the mailing list, then going to one nearby IETF meeting in person, then representing my team at an interim meeting. At this point, I attend most full IETF meetings and interim meetings for the QUIC WG, often in-person but sometimes remotely.
HTTP/2 defines "an optimized mapping of HTTP to TCP." That is, it doesn't attempt to change HTTP and it doesn't attempt to change TCP, but it does attempt to do a better job of running one on top of the other. Almost anything that can be expressed in HTTP/1.1 can be expressed in HTTP/2 -- it's different on the wire, but supports the same syntax. Hang onto this notion that the HTTP Semantics and the transport mapping are distinct things -- we'll need it in a minute[1].
TCP provides an ordered bytestream abstraction, which means it's a pipe -- put data in, it comes out on the other side. HTTP/1.1 was text-based; the client put into the pipe the text of what it wanted the server to do, then waited. The server read the request, did whatever it needed to do, stuffed the answer back into the pipe, then waited.
Want to ask for more than one thing at once? Open multiple pipes. Oh, except that when you do that, you're messing with TCP's congestion control mechanisms -- the pipes don't know about each other and are competing for the same bandwidth. You can wind up in a situation where the pipes cause each other to lose packets and get stuck waiting for retransmissions.
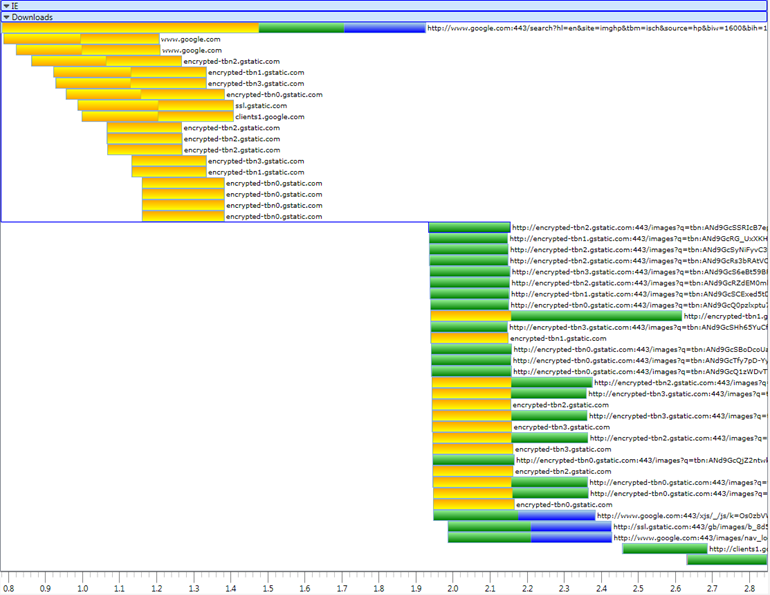
What you see here is the graph of loading a Google image search over HTTP/1.1 -- while you're waiting on the initial request (top line), you speculatively open connections to lots of related domains you remember from last time. When you get the page back, you start loading resources (images, scripts, etc.) from those connections. But sometimes, the browser guesses wrong and has to open a new connection to handle a request. Sometimes it spends time opening a connection, then never uses it.
While text is great for debugging -- you can just look at the packet and see that you've misspelled something! -- it's pretty rotten for parsing. Because people do misspell things. Or use extra spaces. Or capitalize differently. Or use non-ASCII characters without telling you what text encoding they're using. You wind up in a state where it appears to mostly work, until someone fixes a bug somewhere else and then discover your site just broke.
Text is also highly compressible, which means you're sending more bytes than are really needed[2]. That compression problem gets many times worse if you think about the fact that you're often sending painfully large headers with every request. Cookie, User-Agent, and more -- every request, rarely changing, but still there. HTTP has had compression of bodies (the things we're uploading and downloading) for ages, but the headers remained persistently out of reach.
HTTP/2 provides three[3] big improvements to the TCP mapping:
- Binary framing: Down with text and whitespace, up with flags and four-byte integers. Harder for a human to read without help -- but far easier to build a protocol where it's clearly either right or broken.
- Multiplexing: Rather than opening multiple pipes, let's use one pipe and label the pieces of each request/response as we put them in.
- Header compression: Remember what headers have been used before, and provide a short (one-byte) way to say "Yeah, User-Agent hasn't changed in the last half-second." Rather than spending an equal eight bits on each possible octet, make the rare ones more expensive (27 bits for 'ø') so the common ones can be cheap (five bits for 'e').
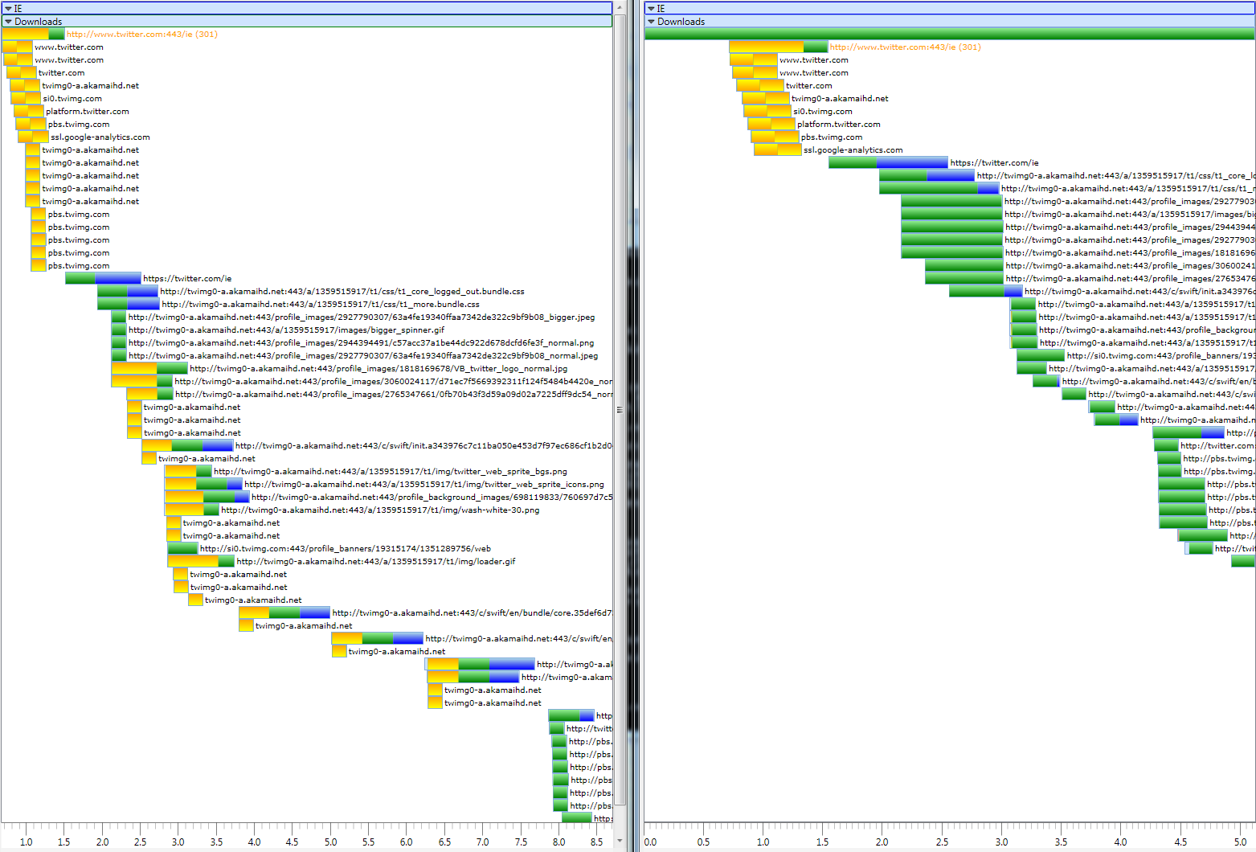
With HTTP/2, the browser can open far fewer connections, requests never wait on a new connection to open, and pages can just load faster.
So what's all that got to do with QUIC? HTTP/2 explicitly decided not to change anything about TCP. We couldn't -- it wasn't in our charter. But that meant there were real problems that were still out of our reach. QUIC is the opposite: it's explicitly chartered to build a new transport that can be used instead of TCP. And then we'll also define how to run HTTP (still unmodified) on top of that.